on
Short Summary: Objects as Points (2019)
Authors: Xingyi Zhou, Dequan Wang, Philipp Krähenbühl
Link to paper: https://arxiv.org/pdf/1904.07850.pdf
Problem
2D-Detection, 3D-Detection, Multi-Person 2D Pose-estimation
Improvement over previous methods
- Anchor-free.
- Faster and more efficient.
- No non-maximum suppression needed.
Method
Predict heatmap of object centers (comparable to keypoint detection). The target is a heatmap per object class that results from a binary map of all the ground-truth object centers of a class (can easily be calculated if ground-truth bounding boxes are given). Additionally small errors in the center location prediction should be penalized weakly since they may still be suitable for object detection. For this reason use a gaussian function to create a (binary color) gradient around object centers on the target heatmap to not punish slight offsets too hard. In addition to the heatmap, the ground-truths bounding box offset and height/width are used as targets in 4 additional feature maps. This means at each location of feature maps the object detector must predict C + 4 values.
Now, given that we have predictions for the object centers in form of a prediction heatmap instead of applying non-maximum suppression we make use of a simpler procedure. We search for local maxima by comparing each prediction with its 8 local neighbor pixel predictions. If the current pixel has higher confidence than the surrounding ones, we assume an object at this position. Finally, the top 100 peaks are taken.
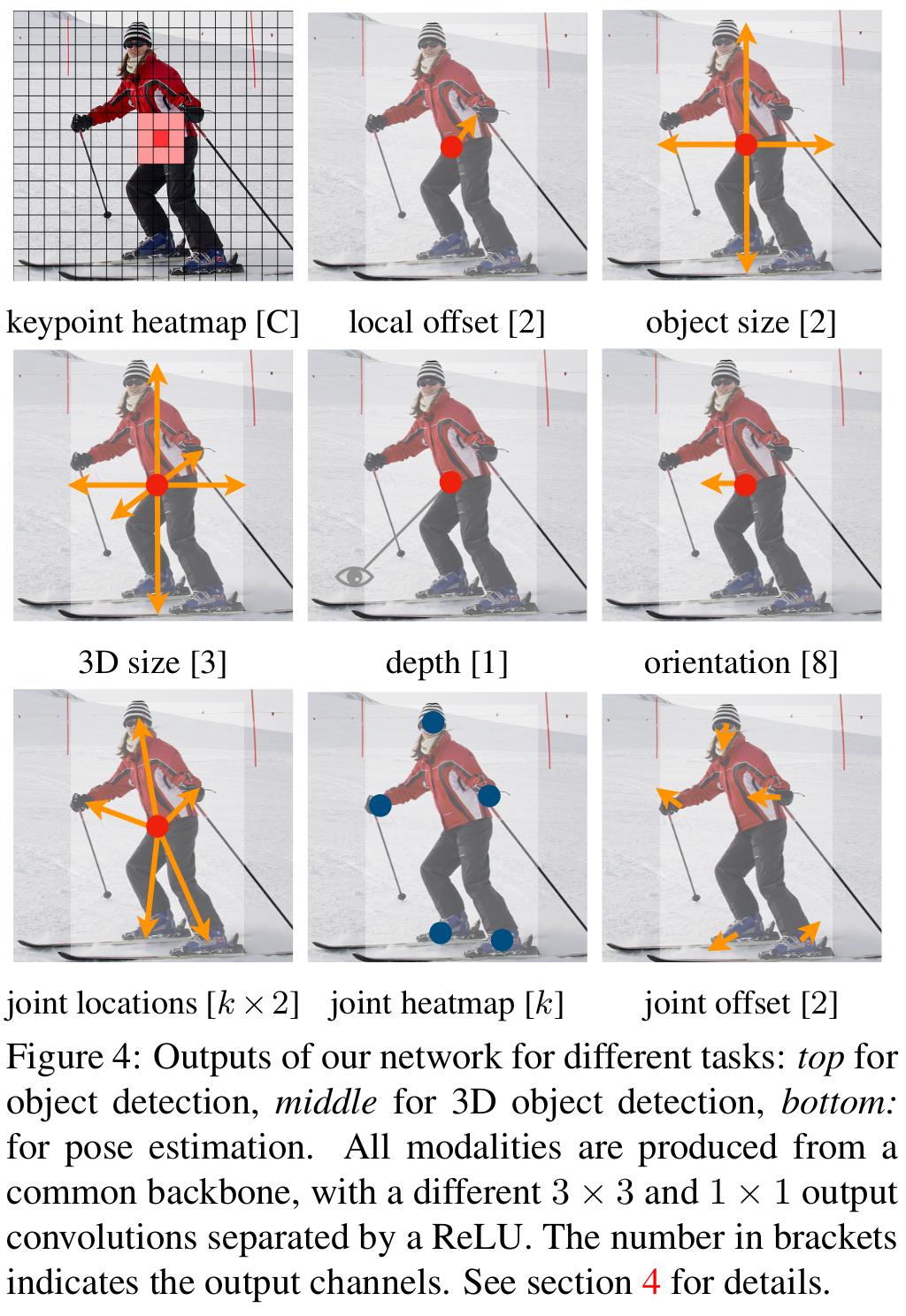
Implementation
Put input image through a convolutional neural network encoder to extract feature maps. Use a encoder that does not downscale the size of the feature maps much (in comparison: Faster-RCNN uses 16x downscaling; here only 4x is used). After the encoder a head for each modality (e.g. classification, bounding box offset, bounding box size for 2D-detection and additionally, depth, 3D-location and 3D-orientation for 3D-detection) is added.